|
Chaoyi Zhou I am a PhD student in Computer Science at Clemson University advised by Prof. Siyu Huang. Previously, I obtanined my M.S. in Computer Science from University of Southern California, where I worked advised by Prof. Yajie Zhao . I received my B.E. in Computer Science and Technology from Nanjing University of Posts and Telecommunications in 2020. My research interests include computer vision and multimodal learning, particularly in 3D reconstruction and visual understanding. |

|
News2026.04: Invited talk at the Clemson AI Research Symposium. 2026.03:I will join UII this summer as a Research Intern!2026.03: FF3R is accepted to CVPR 2026 Findings Track! 2025.09: Bézier Splatting is accepted to NeurIPS 2025! 2025.03: I will join Microsoft this summer as a Research Intern! 2025.01: Latent Radiance Fields is accepted to ICLR 2025! 2024.09: 3DGS-Enhancer is accepted to NeurIPS 2024 as Spotlight (3.5% of 15671 submissions)! 2024.01: I will join Vision and Learning Lab in Clemson University as a PhD student! |
Selected Publications* indicates equal contribution |

|
FF3R: Feedforward Feature 3D Reconstruction from Unconstrained views
Chaoyi Zhou, Run Wang, Feng Luo, Mert D. Pesé, Zhiwen Fan, Yiqi Zhong, Siyu Huang CVPR Findings, 2026 project page / arXiv We introduces FF3R, a fully annotation-free feed-forward framework that unifies geometric and semantic reasoning from unconstrained multi-view image sequences. Extensive experiments on ScanNet and DL3DV-10K demonstrate FF3R's superior performance in novel-view synthesis, open-vocabulary semantic segmentation, and depth estimation, with strong generalization to in-the-wild scenarios, paving the way for embodied intelligence systems that demand both spatial and semantic understanding. |
|
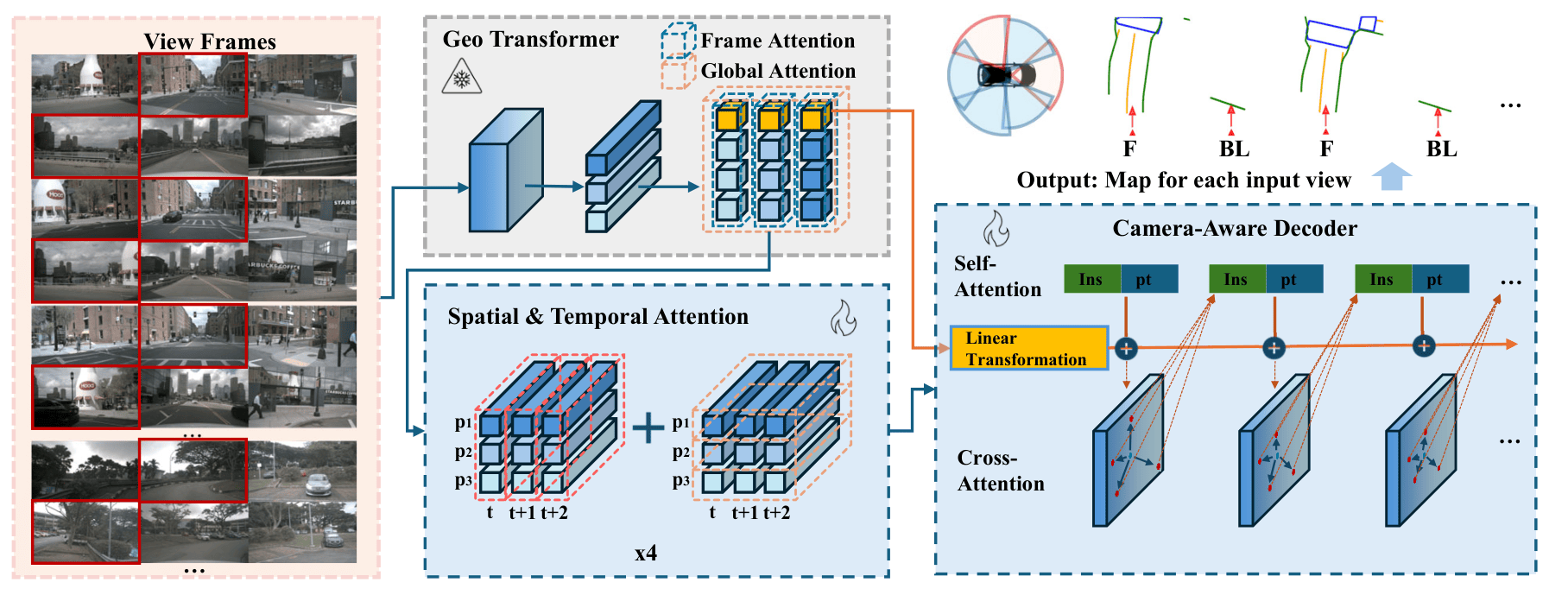
FlexMap: Generalized HD Map Construction from Flexible Camera Configurations
Run Wang, Chaoyi Zhou, Amir Salarpour, Xi Liu, Zhi-Qi Cheng, Feng Luo, Mert D. Pesé, Siyu Huang preprint arXiv We introduce FlexMap, a flexible HD map construction method that adapts to variable camera configurations without architectural changes or retraining. Unlike prior methods fixed to specific multi-camera setups, FlexMap uses a geometry-aware foundation model with cross-frame attention to implicitly encode 3D scene understanding, maintaining robustness to missing views and sensor variations for practical autonomous driving deployment. |

|
Bézier Splatting for Fast and Differentiable Vector Graphics
Xi Liu*, Chaoyi Zhou*, Nanxuan Zhao, Siyu Huang NeurIPS, 2025 project page / arXiv This work introduces a new differentiable VG representation, dubbed Bézier splatting, that enables fast yet high-fidelity VG rasterization. Bézier splatting samples 2D Gaussians along Bézier curves, which naturally provide positional gradients at object boundaries. |

|
Latent Radiance Fields with 3D-aware 2D Representations
Chaoyi Zhou*, Xi Liu*, Feng Luo, Siyu Huang ICLR, 2025 project page / arXiv / code In this work, we propose a method to achieve 3D-aware 2D representations and enable 3D reconstruction in the latent space. Our LRF enables 3D reconstruction on the 2D latent space instead of the image space. It can render high-quality and photorealistic novel views, even for the unbounded scenes. |

|
3DGS-Enhancer: Enhancing Unbounded 3D Gaussian Splatting with View-consistent 2D Diffusion Priors
Xi Liu*, Chaoyi Zhou*, Siyu Huang NeurIPS, 2024 (Spotlight) project page / arXiv / code 3DGS-Enhancer restores view-consistent latent features of rendered novel views and integrates them with the input views through a spatial-temporal decoder. The enhanced views are then used to fine-tune the initial 3DGS model, significantly improving its rendering performance. |
ServiceConference Reviewer: CVPR'26, ICCV'25, ICML'25, ICLR'25, NeurIPS'24,25. |
Award2025.04: Rising Researcher Award from Clemson University 2025.03: ICLR Student Travel Award |